ForkJoinPool is a powerful Java class used for processing computationally intensive tasks. It works by breaking down tasks into smaller subtasks and then executing them in parallel. This thread pool operates using a divide-and-conquer strategy, which enables it to execute tasks concurrently, increasing throughput and reducing processing time.
One of the unique features of ForkJoinPool is the work-stealing algorithm it uses to optimize performance. When a worker thread finishes its assigned tasks, it will steal tasks from other threads, ensuring that all threads are working efficiently, and no computer resources are wasted.
ForkJoinPool is used extensively in Java’s parallel streams and CompletableFutures, allowing developers to execute tasks concurrently with ease. Additionally, other JVM languages like Kotlin and Akka use this framework to build message-driven applications that require high concurrency and resilience.
Thread pooling with ForkJoinPool
The ForkJoinPool class stores workers, which are processes being run on each CPU core from the machine. Each of those processes is stored in a deque, which stands for double-ended queue. As soon as a worker thread runs out of tasks, it begins stealing tasks from other workers.
First, there will be the process of forking the task; this means that a big task will be broken down into smaller tasks that can be executed in parallel. Once all subtasks are completed, they are rejoined. The ForkJoinPool class then provides one result, as shown in Figure 1.
 IDG
IDGFigure 1. ForkJoinPool in action
When the task is submitted in a ForkJoinPool, the process will be divided into smaller processes and pushed to a shared queue.
Once the fork() method is invoked, tasks are invoked in parallel until the base condition is true. Once processing is forked, the join() method ensures that threads wait for each other until the process has been finalized.
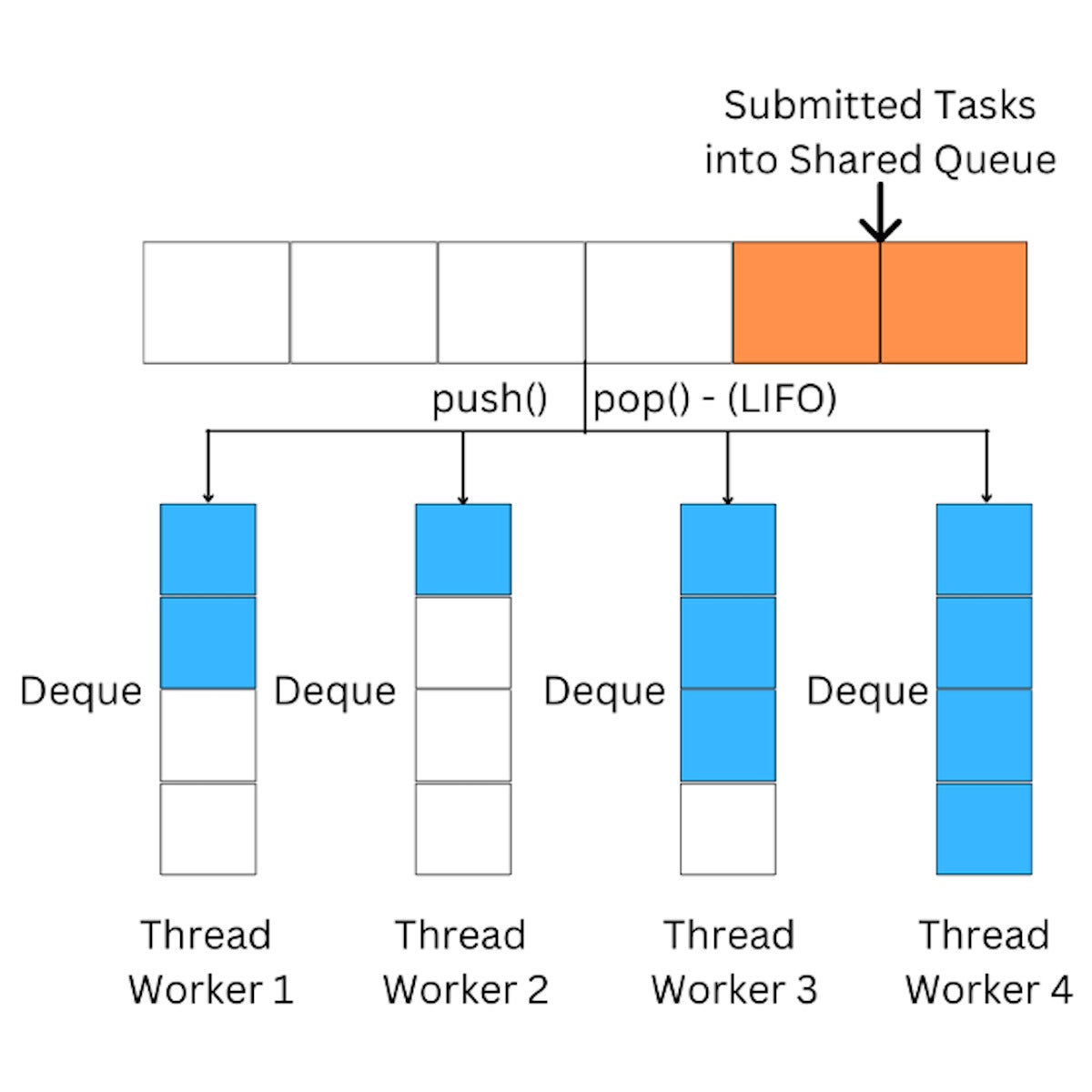
All the tasks initially will be submitted to a main queue, and this main queue will push tasks to the worker threads. Notice that tasks are inserted using the LIFO (last-in, first-out) strategy which is the same as the stack data structure.
Another important point is that the ForkJoinPool uses deques to store tasks. This gives the ability to use either LIFO or FIFO (first-in, first-out), which is necessary for the work-stealing algorithm.
 IDG
IDGFigure 2. ForkJoinPool uses Deques to store tasks
The work-stealing algorithm
Work-stealing in ForkJoinPool is an effective algorithm that enables efficient use of computer resources by balancing the workload across all available threads in the pool.
When a thread becomes idle, instead of remaining inactive, it will attempt to steal tasks from other threads that are still busy with their assigned work. This process maximizes the utilization of computing resources and ensures that no thread is overburdened while others remain idle.
The key concept behind the work-stealing algorithm is that each thread has its own deque of tasks, which it executes in a LIFO order.
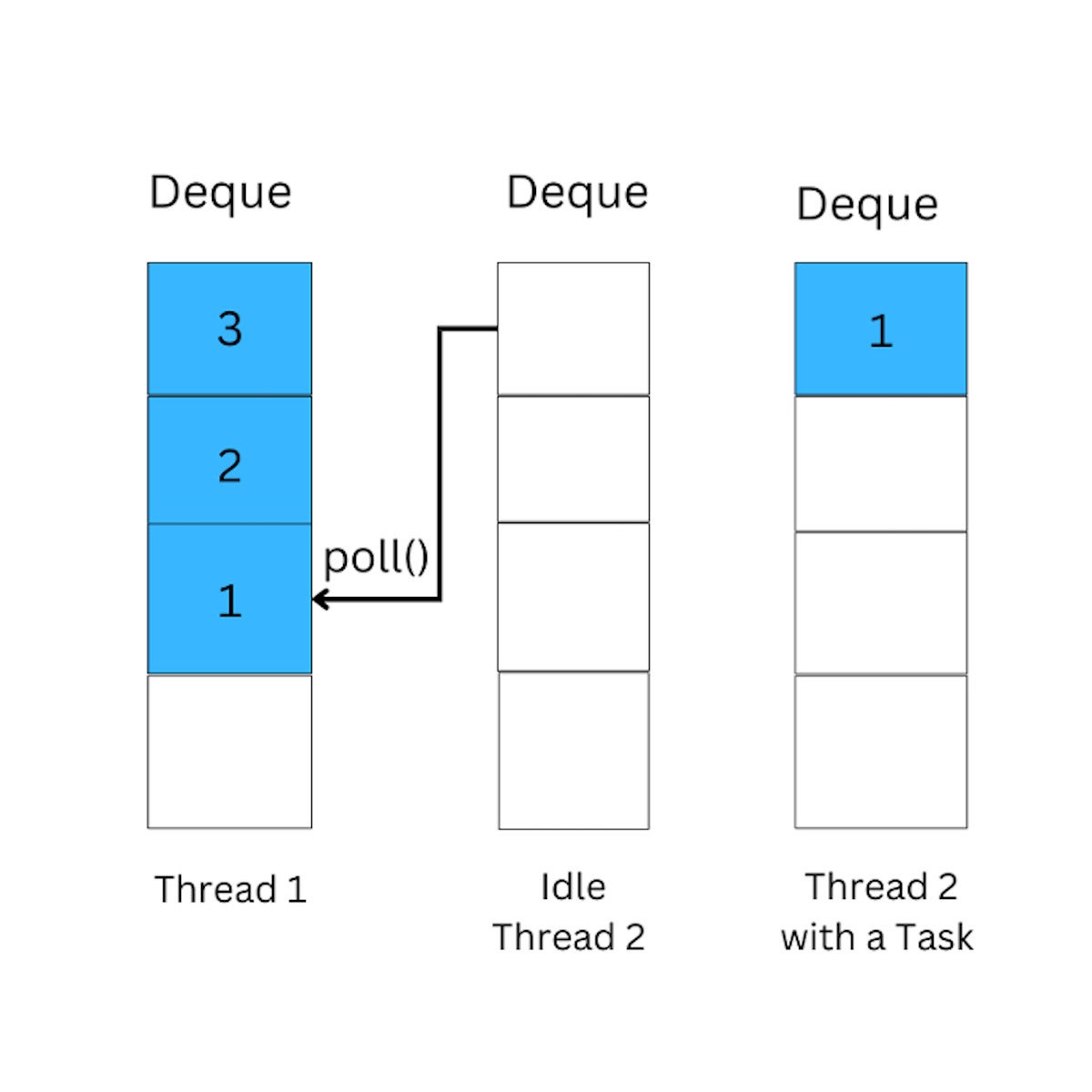
When a thread finishes its own tasks and becomes idle, it will attempt to “steal” tasks from the end of another thread’s deque, following a FIFO strategy, the same as the queue data structure. This allows the idle thread to pick up the tasks that have waited for the longest time, reducing the overall waiting time and increasing throughput.
In the following diagram, Thread 2 steals a task from Thread 1 by polling the last element from Thread 1’s deque, and then executes the task. The stolen task is typically the oldest one in the deque, which ensures that the workload is evenly distributed among all threads in the pool.
 IDG
IDGFigure 3. An illustration of ForkJoinPool’s work-stealing algorithm
Overall, ForkJoinPool‘s work-stealing algorithm is a powerful feature that can significantly improve the performance of parallel applications by ensuring that all available computing resources are utilized efficiently.
ForkJoinPool’s main classes
Let’s take a quick look at the main classes that support processing using ForkJoinPool.
ForkJoinPool: Creates a thread pool to use the ForkJoin framework. It works similarly to other thread pools. The most important method from this class iscommonPool(), which creates theForkJointhread pool.RecursiveAction: The main function of this class is to compute recursive actions. Remember that in thecompute()method, we don’t return a value. This is because the recursion happens within thecompute()method.RecursiveTask: This class works similarly to theRecursiveAction, with the difference that thecompute()method will return a value.
Using RecursiveAction
To use the RecursiveAction capabilities we need to inherit it and override the compute() method. Then, we create the subtasks with the logic that we want to implement.
In the following code example, we’ll calculate the number that is double each number in the array in parallel and recursively. We are limited to calculate two by two array elements in parallel.
As you can see, the fork() method invokes the compute() method. As soon as the whole array has the sum from each of its elements, the recursive invocations stops. Once all the elements of the array are summed recursively, we show the result.
Listing 1. An example of RecursiveAction
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
public class ForkJoinDoubleAction {
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
int[] array = {1, 5, 10, 15, 20, 25, 50};
DoubleNumber doubleNumberTask = new DoubleNumber(array, 0, array.length);
// Invokes compute method
forkJoinPool.invoke(doubleNumberTask);
System.out.println(DoubleNumber.result);
}
}
class DoubleNumber extends RecursiveAction {
final int PROCESS_THRESHOLD = 2;
int[] array;
int startIndex, endIndex;
static int result;
DoubleNumber(int[] array, int startIndex, int endIndex) {
this.array = array;
this.startIndex = startIndex;
this.endIndex = endIndex;
}
@Override
protected void compute() {
if (endIndex - startIndex <= PROCESS_THRESHOLD) {
for (int i = startIndex; i < endIndex; i++) {
result += array[i] * 2;
}
} else {
int mid = (startIndex + endIndex) / 2;
DoubleNumber leftArray = new DoubleNumber(array, startIndex, mid);
DoubleNumber rightArray = new DoubleNumber(array, mid, endIndex);
// Invokes the compute method recursively
leftArray.fork();
rightArray.fork();
// Joins results from recursive invocations
leftArray.join();
rightArray.join();
}
}
}
The output from this calculation is 252.
The important point to remember from RecursiveAction is that it doesn’t return a value. It’s also possible to break down the process by using the divide-and-conquer strategy to boost performance.
That’s what we’ve done in Listing 1, instead of calculating the double of each array’s element, we did that in parallel by breaking the array into parts.
It is also important to note that RecursiveAction is most effective when used for tasks that can be efficiently broken down into smaller subproblems.
Therefore, RecursiveAction and ForkJoinPool should be used for computationally intensive tasks where the parallelization of work can lead to significant performance improvements. Otherwise, the performance will be even worse due to the creation and management of threads.
RecursiveTask
In this next example, let’s explore a simple program that breaks in the middle recursively until it reaches to the base condition. In this case, we are using the RecursiveTask class.
The difference between RecursiveAction and RecursiveTask is that with RecursiveTask, we can return a value in the compute() method.
Listing 2. An example of RecursiveTask
import java.util.List;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveTask;
public class ForkJoinSumArrayTask extends RecursiveTask<Integer> {
private final List<Integer> numbers;
public ForkJoinSumArrayTask(List<Integer> numbers) {
this.numbers = numbers;
}
@Override
protected Integer compute() {
if (numbers.size() <= 2) {
return numbers.stream().mapToInt(e -> e).sum();
} else {
int mid = numbers.size() / 2;
List<Integer> list1 = numbers.subList(0, mid);
List<Integer> list2 = numbers.subList(mid, numbers.size());
ForkJoinSumArrayTask task1 = new ForkJoinSumArrayTask(list1);
ForkJoinSumArrayTask task2 = new ForkJoinSumArrayTask(list2);
task1.fork();
return task1.join() + task2.compute();
}
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
List<Integer> numbers = List.of(1, 3, 5, 7, 9);
int output = forkJoinPool.invoke(new ForkJoinSumArrayTask(numbers));
System.out.println(output);
}
}
Here, we recursively break down the array in the middle until it reaches to the base condition.
Once we have the main array broken, we send list1 and list2 to the ForkJoinSumArrayTask, then we fork the task1, which executes the compute() method and the other part of the array in parallel.
Once the recursion process reaches the base condition, the join method is invoked, joining the results.
The output in this case is 25.
When to Use ForkJoinPool
ForkJoinPool shouldn’t be used in every situation. As mentioned, it’s better to use it for highly-intensive concurrent processes. Let’s see specifically what those situations are:
- Recursive tasks:
ForkJoinPoolis well-suited for executing recursive algorithms such as quicksort, merge sort, or binary search. These algorithms can be broken down into smaller subproblems and executed in parallel, which can result in significant performance improvements. - Embarrassingly parallel problems: If you have a problem that can be easily divided into independent subtasks, such as image processing or numerical simulations, you can use
ForkJoinPoolto execute the subtasks in parallel. - High-concurrency scenarios: In high-concurrency scenarios, such as web servers, data processing pipelines, or other high-performance applications, you can use
ForkJoinPoolto execute tasks in parallel across multiple threads, which can help to improve performance and throughput.
Summary
In this article, you saw how to use the most important ForkJoinPool functionalities to execute heavy operations in separate CPU cores. Let’s conclude with the key points from this article:
ForkJoinPoolis a thread pool that uses a divide-and-conquer strategy to execute tasks recursively.- It is used by JVM languages such as Kotlin and Akka to build message-driven applications.
ForkJoinPoolexecutes tasks in parallel, enabling efficient use of computer resources.- The work-stealing algorithm optimizes resource utilization by allowing idle threads to steal tasks from busy ones.
- Tasks are stored in a double-ended queue, with the LIFO strategy used for storage and FIFO for stealing.
- The main classes in the
ForkJoinPoolframework includeForkJoinPool,RecursiveAction, andRecursiveTask:RecursiveActionis used to compute recursive actions and doesn’t return any values.RecursiveTaskis similar but returns a value.- The
compute()method is overridden in both classes to implement custom logic. - The
fork()method invokes thecompute()method and breaks down the task into smaller subtasks. - The
join()method waits for subtasks to complete and merges their results. ForkJoinPoolis commonly used with parallel streams andCompletableFuture.
Copyright © 2023 IDG Communications, Inc.
Source link