The IT world revolves around servers – we set up, manage, and scale them, we communicate with them, deploy software onto them, and restrict access to them. In the end, it is difficult to imagine our lives without them. However, in this “serverfull” world, an idea of serverless architecture arose. A relatively new approach to building applications without direct access to the servers required to run them. Does it mean that the servers are obsolete, and that we no longer should use them? In this article, we will explore what it means to build a serverless application, how it compares to the well-known microservice design, what are the pros and cons of this new method and how to use the AWS Cloud Development Kit framework to achieve that.
Background
There was a time when the world was inhabited by creatures known as “monolith applications”. Those beings were enormous, tightly coupled, difficult to manage, and highly resource-consuming, which made the life of tech people a nightmare.
Out of that nightmare, a microservice architecture era arose, which was like a new day for software development. Microservices are small independent processes communicating with each other through their APIs. Each microservice can be developed in a different programming language, best suited for its job, providing a great deal of flexibility for developers. Although the distributed nature of microservices increased the overall architectural complexity of the systems, it also provided the biggest benefit of the new approach, namely scalability, coming from the possibility to scale each microservice individually based on its resource demands.
The microservice era was a life changer for the IT industry. Developers could focus on the design and development of small modular components instead of struggling with enormous black box monoliths. Managers enjoyed improvements in efficiency. However, microservice architecture still posed a huge challenge in the areas of deployment and infrastructure management for distributed systems. What is more, there were scenarios when it was not as cost-effective as it could be. That is how the software architecture underwent another major shift. This time towards the serverless architecture epoch.
What is serverless architecture?
Serverless, a bit paradoxically, does not mean that there are no servers. Both server hardware and server processes are present, exactly as in any other software architecture. The difference is that the organization running a serverless application is not owning and managing those servers. Instead, they make use of third-party Backend as a Service (BaaS) and/or Function as a Service platform.
- Backend as a Service (BaaS) is a cloud service model where the delivery of services responsible for server-side logic is delegated to cloud providers. This often includes services such as: database management, cloud storage, user authentication, push notifications, hosting, etc. In this approach, client applications, instead of talking to their dedicated servers, directly operate on those cloud services.
- Function as a Service (FaaS) is a way of executing our code in stateless, ephemeral computing environments fully managed by third-party providers without thinking about the underlying servers. We simply upload our code, and the FaaS platform is responsible for running it. Our functions can then be triggered by events such as HTTP(S) requests, schedulers, or calls from other cloud services. One of the most popular implementations of FaaS is the AWS Lambda service, but each cloud provider has its corresponding options.

In this article, we will explore the combination of both BaaS and FaaS approaches as most enterprise-level solutions combine both of them into a fully functioning system.
Note: This article is often referencing services provided by AWS. However, it is important to note that the serverless architecture approach is not cloud-provider-specific and most of the services mentioned as part of the AWS platform have their equivalents in other cloud platforms.
Serverless Architecture Design
We know a bit of theory, so let us look now at a practical example. The figure 1 presents an architecture diagram of a user management system created with the serverless approach.
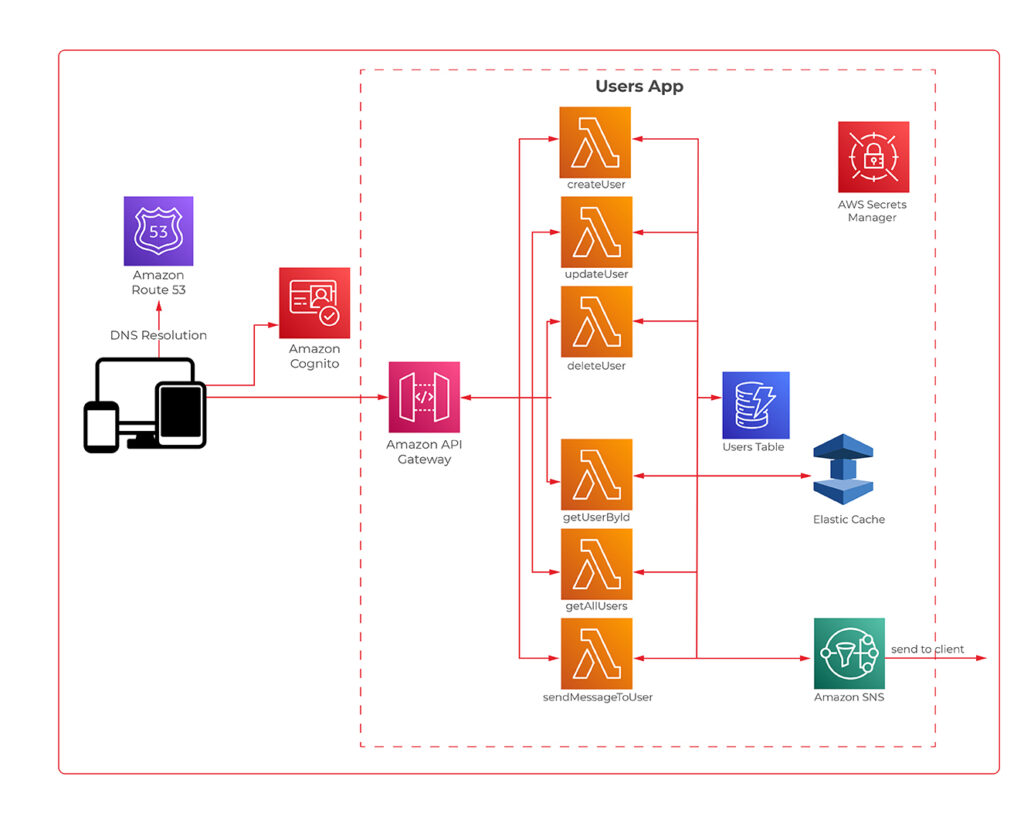
The system utilizes Amazon Cognito for user authentication and authorization, ensuring that only authorized parties access our API. Then we have the API Gateway, which deals with all the routing, requests throttling, DDOS protection etc. API Gateway also allows us to implement custom authorizers if we can’t or don’t want to use Amazon Cognito. The business logic layer consists of Lambda Functions. If you are used to the microservice approach, you can think of each lambda as a separate set of a controller endpoint and service method, handling a specific type of request. Lambdas further communicate with other services such as databases, caches, config servers, queues, notification services, or whatever else our application may require.
The presented diagram demonstrates a relatively simple API design. However, it is good to bear in mind that the serverless approach is not limited to APIs. It is also perfect for more complex solutions such as data processing, batch processing, event ingestion systems, etc.
Serverless vs Microservices
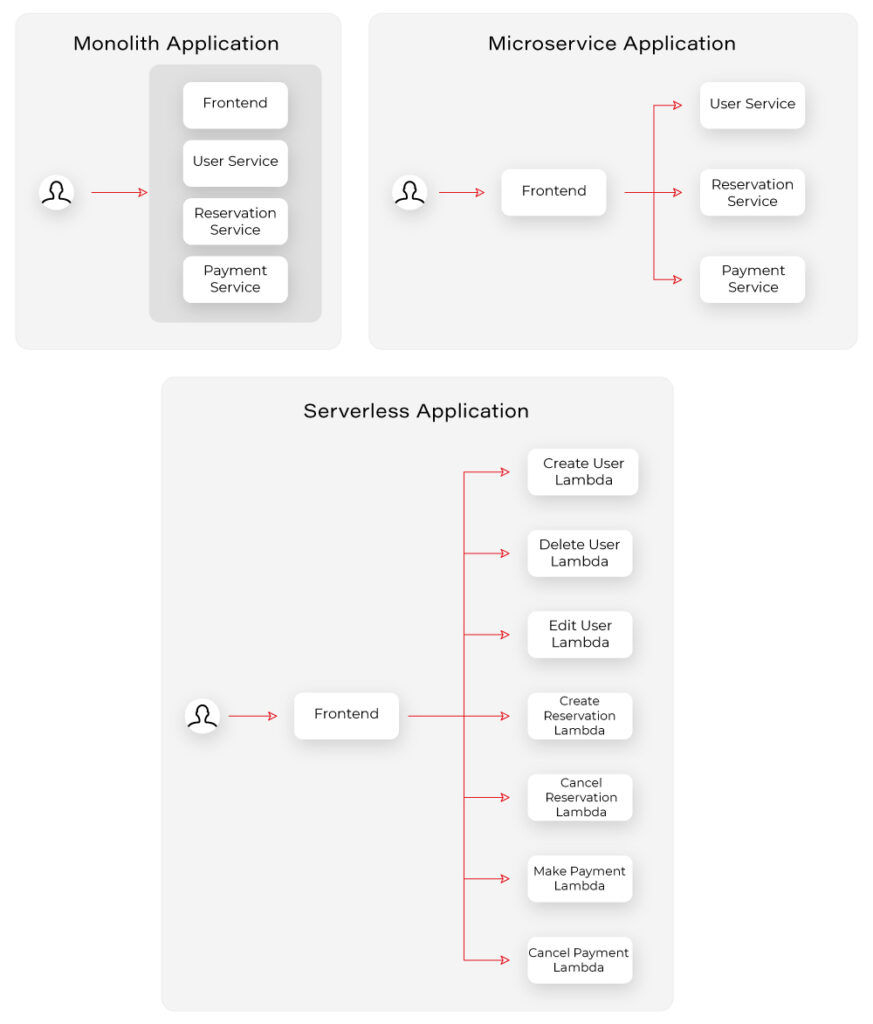
Microservice-oriented architecture broke down the long-lasting realm of monolith systems through the division of applications into small, loosely coupled services that could be developed, deployed, and maintained independently. Those services had distinct responsibilities and could communicate with each other through APIs, constituting together a much larger and complex system. Up till this point, serverless does not differ much from the microservice approach. It also divides a system into smaller, independent components, but instead of services, we usually talk about functions.
So, what’s the difference? The microservices are standalone applications, usually packaged as lightweight containers and run on physical servers (commonly in the cloud), which you can access, manage and scale if needed. Those containers need to be supervised (orchestrated) with the use of tools such as Kubernetes. So speaking simply, you divide your application into smaller independent parts, package them as containers, deploy on servers, and orchestrate their lifecycle.
In comparison, when it comes to serverless functions, you only write your function code, upload it to the FaaS provider platform, and the cloud provider handles its packaging, deployment, execution, and scaling without showing you (or giving you access to) physical resources required to run it. What is more, when you deploy microservices, they are always active, even when they do not perform any processing, on the servers provisioned to them. Therefore, you need to pay for required host servers on a daily or monthly basis, in contrast to the serverless functions, which are only brought to life for their time of execution, so if there are no requests they do not use any resources.
Pros & Cons of Serverless Computing
Pros:
- Pricing – Serverless works in a pay-as-you-go manner, which means that you only pay for those resources which you actually use, with no payment for idle time of the servers and no in-front dedication. This is especially beneficial for applications with infrequent traffic or startup organizations.
- Operational costs and complexity – The management of your infrastructure is delegated almost entirely to the cloud provider. This frees up your team allocation, decreases the probability of error on your side, and automates downtime handling leading to the overall increase in the availability of your system and the decrease in operational costs.
- Scalability by design – Serverless applications are scalable by nature. The cloud provider handles scaling up and down of resources automatically based on the traffic.
Cons:
- It is a much less mature approach than microservices which means a lot of unknowns and spaces for bad design decisions exist.
- Architectural complexity – Serverless functions are much more granular than microservices, and that can lead to higher architectural complexity, where instead of managing a dozen of microservices, you need to handle hundreds of lambda functions.
- Cloud provider specific solutions – With microservices packaged as containers, it didn’t matter which cloud provider you used. That is not the case for serverless applications which are tightly bound to the services provided by the cloud platform.
- Services limitations – some Faas and BaaS services have limitations such as a maximum number of concurrent requests, memory, timeouts, etc. which are often customizable but only to a certain point (e.g., default AWS Lambda execution quota equals 1000).
- Cold starts – Serverless applications can introduce response delays when a new instance handles its first request because it needs to boot up, copy application code, etc. before it can run the logic.
How much does it really cost?
One of the main advantages of the serverless design is its pay-as-you-go model, which can greatly decrease the overall costs of your system. However, does it always lead to lesser expenses? For this consideration, let us look at the pricing of some of the most common AWS services.
| Service | Price |
| API Gateway | 3.50$ per 1M requests (REST Api) |
| Lambda | 0.20$ per 1M request |
| SQS | First 1M free, then 0.40& per 1M requests |
Those prices seem low, and in many cases, they will lead to very cheap operational costs of running serverless applications. Having that said, there are some scenarios where serverless can get much more expensive than other architectures. Let us consider a system that handles 5 mln requests per hour. Having it designed as a serverless architecture will lead to the cost of API Gateway only equal to:
$3.50 * 5 * 24 * 30 = $12,600/month
In this scenario, it could be more efficient to have an hourly rate-priced load balancer and a couple of virtual machines running. Then again, we would have to take into consideration the operational cost of setting up and managing the load balancer and VMs. As you can see, it all depends on the specific use case and your organization. You can read more about this scenario in this article.
AWS Cloud Development Kit
At this point, we know quite a lot about serverless computing, so now, let’s take a look at how we can create our serverless applications. First of all, we can always do it manually through the cloud provider’s console or CLI. It may be a valuable educational experience, but we wouldn’t recommend it for real-life systems. Another well-known solution is using Infrastructure as a Code (IaaS), such as AWS Cloud Formation service. However, in 2019 AWS introduced another possibility which is AWS Cloud Development Kit (CDK).
AWS CDK is an open-source software development framework which lets you define your architectures using traditional programming languages such as Java, Python, Javascript, Typescript, and C#. It provides you with high-level pre-configured components called constructs which you can use and further extend in order to build your infrastructures faster than ever. AWS CDK utilizes Cloud Formation behind the scenes to provision your resources in a safe and repeatable manner.
We will now take a look at the CDK definitions of a couple of components from the user management system, which the architecture diagram was presented before.

Main Stack Definition
export class UserManagerServerlessStack extends cdk.Stack {
private static readonly API_ID = 'UserManagerApi';
constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
const cognitoConstruct = new CognitoConstruct(this)
const usersDynamoDbTable = new UsersDynamoDbTable(this);
const lambdaConstruct = new LambdaConstruct(this, usersDynamoDbTable);
new ApiGatewayConstruct(this, cognitoConstruct.userPoolArn, lambdaConstruct);
}
}
API Gateway
export class ApiGatewayConstruct extends Construct {
public static readonly ID = 'UserManagerApiGateway';
constructor(scope: Construct, cognitoUserPoolArn: string, lambdas: LambdaConstruct) {
super(scope, ApiGatewayConstruct.ID);
const api = new RestApi(this, ApiGatewayConstruct.ID, {
restApiName: 'User Manager API'
})
const authorizer = new CfnAuthorizer(this, 'cfnAuth', {
restApiId: api.restApiId,
name: 'UserManagerApiAuthorizer',
type: 'COGNITO_USER_POOLS',
identitySource: 'method.request.header.Authorization',
providerArns: [cognitoUserPoolArn],
})
const authorizationParams = {
authorizationType: AuthorizationType.COGNITO,
authorizer: {
authorizerId: authorizer.ref
},
authorizationScopes: [`${CognitoConstruct.USER_POOL_RESOURCE_SERVER_ID}/user-manager-client`]
};
const usersResource = api.root.addResource('users');
usersResource.addMethod('POST', new LambdaIntegration(lambdas.createUserLambda), authorizationParams);
usersResource.addMethod('GET', new LambdaIntegration(lambdas.getUsersLambda), authorizationParams);
const userResource = usersResource.addResource('{userId}');
userResource.addMethod('GET', new LambdaIntegration(lambdas.getUserByIdLambda), authorizationParams);
userResource.addMethod('POST', new LambdaIntegration(lambdas.updateUserLambda), authorizationParams);
userResource.addMethod('DELETE', new LambdaIntegration(lambdas.deleteUserLambda), authorizationParams);
}
}
CreateUser Lambda
export class CreateUserLambda extends Function {
public static readonly ID = 'CreateUserLambda';
constructor(scope: Construct, usersTableName: string, layer: LayerVersion) {
super(scope, CreateUserLambda.ID, {
...defaultFunctionProps,
code: Code.fromAsset(resolve(__dirname, `../../lambdas`)),
handler: 'handlers/CreateUserHandler.handler',
layers: [layer],
role: new Role(scope, `${CreateUserLambda.ID}_role`, {
assumedBy: new ServicePrincipal('lambda.amazonaws.com'),
managedPolicies: [
ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole'),
]
}),
environment: {
USERS_TABLE: usersTableName
}
});
}
}
User DynamoDB Table
export class UsersDynamoDbTable extends Table {
public static readonly TABLE_ID = 'Users';
public static readonly PARTITION_KEY = 'id';
constructor(scope: Construct) {
super(scope, UsersDynamoDbTable.TABLE_ID, {
tableName: `${Aws.STACK_NAME}-Users`,
partitionKey: {
name: UsersDynamoDbTable.PARTITION_KEY,
type: AttributeType.STRING
} as Attribute,
removalPolicy: RemovalPolicy.DESTROY,
});
}
}
The code with a complete serverless application can be found on github: https://github.com/mkapiczy/user-manager-serverless
All in all, serverless architecture is becoming an increasingly attractive solution when it comes to the design of IT systems. Knowing what it is all about, how it works, and what are its benefits and drawbacks will help you make good decisions on when to stick to the beloved microservices and when to go serverless in order to help your organization grow.
Source link