A streaming database is a type of database that is designed specifically to process large amounts of real-time streaming data. Unlike traditional databases, which store data in batches before processing, a streaming database processes data as soon as it is generated, allowing for real-time insights and analysis. Unlike traditional stream processing engines that do not persist data, a streaming database can store data and respond to user data access requests. Streaming databases are ideal for latency-critical applications such as real-time analytics, fraud detection, network monitoring, and the Internet of Things (IoT) and can simplify the technology stack.
Brief History
The concept of a streaming database was first introduced in academia in 2002. A group of researchers from Brown, Brandeis, and MIT pointed out the demand for managing data streams inside databases and built the first streaming database, Aurora. A few years later, the technology was adopted by large enterprises. The top three database vendors, Oracle, IBM, and Microsoft, consecutively launched their stream processing solutions known as Oracle CQL, IBM System S, and Microsoft SQLServer StreamInsight. Instead of developing a streaming database from scratch, these vendors have directly integrated stream processing functionality into their existing databases.
Since the late 2000s, developers inspired by MapReduce have separated stream processing functionality from database systems and developed large-scale stream processing engines, including Apache Storm, Apache Samza, Apache Flink, and Apache Spark Streaming. These systems were designed to continuously process ingested data streams and deliver results to downstream systems. However, compared to streaming databases, stream processing engines do not store data and, therefore, cannot serve user-initiated ad-hoc queries.
Streaming databases keep evolving in parallel with stream processing engines. Two streaming databases, PipelineDB and KsqlDB, were developed in the 2010s and were popular then. In the early 2020s, a few cloud-based streaming databases, like RisingWave, Materialize, and DeltaStream, emerged. These products aim to provide users with streaming database services in the cloud. To achieve that objective, the focus is on designing an architecture that fully utilizes resources on the cloud to achieve unlimited horizontal scalability and supreme cost efficiency.
Typical Use Cases
Real-time applications need streaming databases.
Streaming databases are well-suited for real-time applications that demand up-to-date results with a freshness requirement ranging from sub-seconds to minutes. Applications like IoT and network monitoring require sub-second latency, and latency requirements for applications like ad recommendations, stock dashboarding, and food delivery can range from hundreds of milliseconds to several minutes. Streaming databases continuously deliver results at low latency and can be a good fit for these applications.
Some applications are not freshness sensitive and can tolerate delays of tens of minutes, hours, or even days. Some representative applications include hotel reservations and inventory tracking. In these cases, users may consider using either streaming databases or traditional batch-based databases. They should decide based on other factors, such as cost efficiency, flexibility, and tech stack complexity.
Streaming databases are commonly used alongside other data systems in real-time applications to facilitate two classic types of use cases: streaming ingestion (ETL) and streaming analytics.
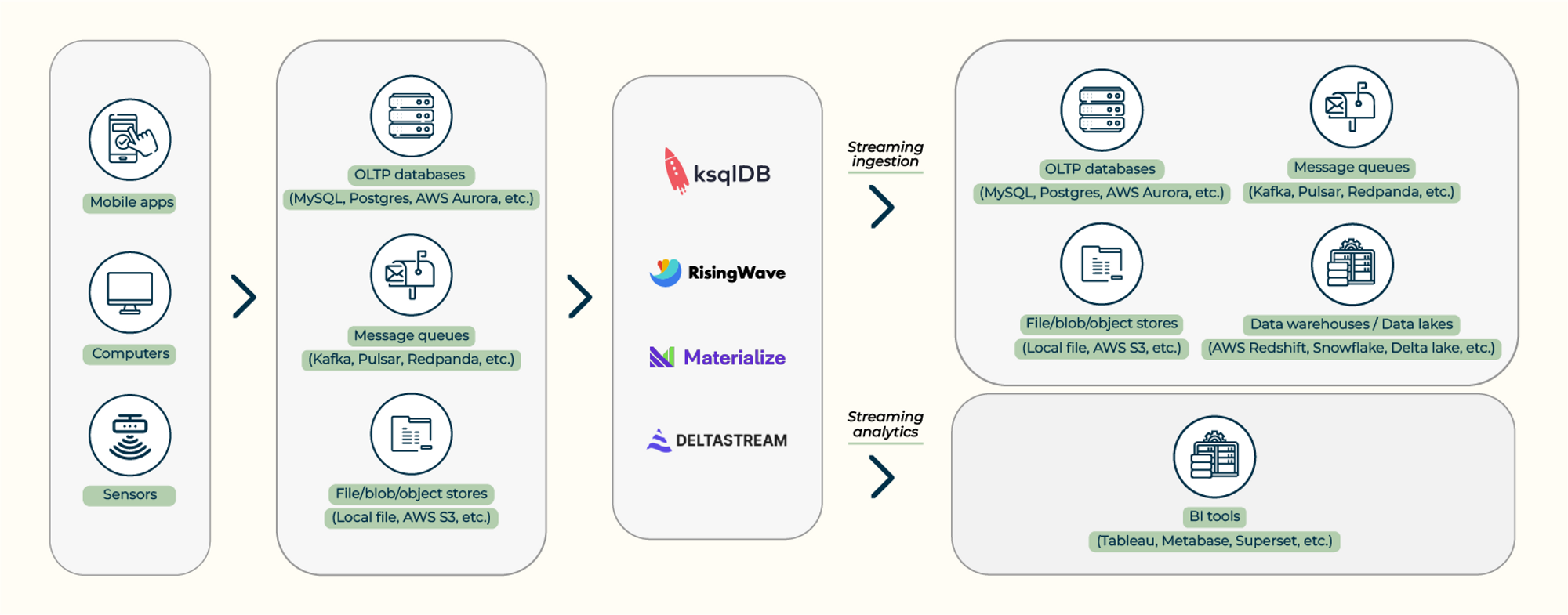
Streaming databases are commonly integrated with other modern data systems to facilitate two types of use cases: streaming ingestion (ETL) and streaming analytics.
Streaming Ingestion (ETL)
Streaming ingestion provides a continuous flow of data from one set of systems to another. Developers can use a streaming database to clean streaming data, join multiple streams, and move the joined results into downstream systems in real time. In real-world scenarios, data ingested into the streaming databases typically come from OLTP databases, messaging queues, or storage systems. After processing, the results are most likely to be dumped back into these systems or inserted into data warehouses or data lakes.
Streaming Analytics
Streaming analytics focuses on performing complex computations and delivering fresh results on-the-fly. Data typically comes from OLTP databases, message queues, and storage systems in the streaming analytics scenario. Results are usually ingested into a serving system to support user-triggered requests. A streaming database can also serve queries on its own. Users can connect a streaming database directly with a BI tool to visualize results.
With the growing demand for real-time machine learning, streaming databases have also become a crucial tool for enabling agile feature engineering. By utilizing streaming databases to store transformed data as features, developers can respond promptly to changing data patterns and new events. Streaming databases allow for real-time ingestion, processing, and transformation of data into meaningful features that can enhance the accuracy and efficiency of machine learning models while also reducing data duplication and improving data quality. This empowers organizations to make faster and more informed decisions, optimize their machine-learning workflows, and gain a competitive advantage.
Streaming Databases vs. Traditional Databases
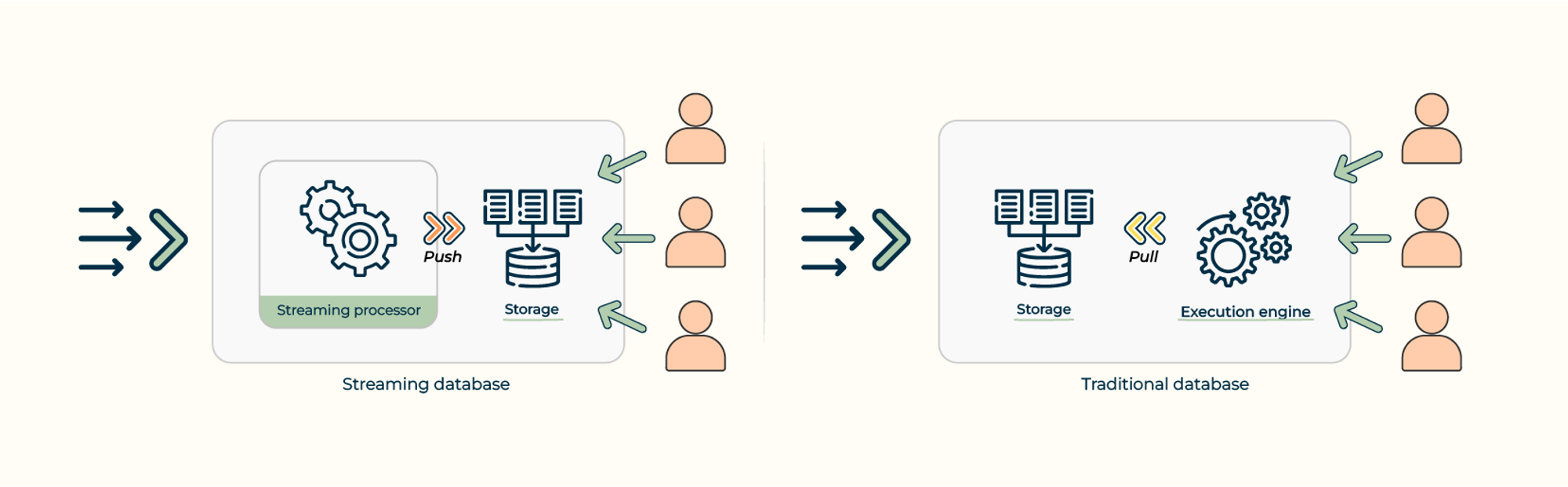
Difference between a streaming database and a traditional database.
Traditional databases are designed to store large amounts of batch data and provide fast, consistent access to that data through transactions and queries. They are often optimized for processing complex operations, such as aggregations and joins, that manipulate the data in bulk. Traditional databases’ execution models are often referred to as Human-Active, DBMS-Passive (HADP) models. That is, a traditional database passively stores data, and queries actively initiated by humans trigger computations. Examples of traditional databases include OLTP databases like MySQL and PostgreSQL and OLAP databases like DuckDB and ClickHouse.
Streaming databases, on the other hand, are designed to incrementally process a large volume of continuously ingested data on-the-fly, and provide low-latency access to the data and results for further processing and analysis. They are optimized for processing data as soon as it arrives rather than bulk processing after data is persisted. Streaming databases’ execution models are often called DBMS-active, Human-Passive (DAHP) models. A streaming database actively triggers computation as data comes in, and humans passively receive results from the database. Examples of streaming databases include PipelineDB, KsqlDB, and RisingWave.
Streaming Databases vs. OLTP Databases
An OLTP database is ACID-compliant and can process concurrent transactions. In contrast, a streaming database does not guarantee ACID compliance and, therefore, cannot be used to support transactional workloads. In terms of data correctness, streaming databases enforce consistency and completeness. A well-designed streaming database should guarantee the following two properties:
- Exactly-once semantics, meaning that every single data event will be processed once and only once, even if a system failure occurs.
- Out-of-order processing means that users can enforce a streaming database to process data events in a predefined order, even if data events arrive out of order.
Streaming Databases vs. OLAP Databases
An OLAP database is optimized for efficiently answering user-initiated analytical queries. OLAP databases typically implement columnar stores and a vectorized execution engine to accelerate complex query processing over large amounts of data. OLAP databases are best suited for use cases where interactive queries are essential. Different from OLAP databases, streaming databases focus more on the resulting freshness, and they use an incremental computation model to optimize latency. Streaming databases typically do not adopt column stores but may implement vectorized execution for query processing.
Conclusion
In conclusion, a streaming database is an essential system for organizations that require real-time insights from large amounts of data. By providing real-time processing, scalability, and reliability, a streaming database can help organizations make better decisions, identify opportunities, and respond to threats in real time.
Source link