
This article is about how Apache Doris helps you import data and conduct Change Data Capture (CDC) from upstream databases like MySQL to Doris based on Flink streaming. But first of all, you might ask: What is Apache Doris and why would I bother to do so?
Well, Apache Doris is an open-source real-time analytical data warehouse that supports both high-concurrency point queries and high-throughput complex analysis. It provides sub-second analytic query capabilities and comes in handy in multi-dimensional analysis, dashboarding, and other real-time data services.
Overview
- How to perform end-to-end data synchronization within seconds
- How to ensure real-time data visibility
- How to smoothen the writing of massive small files
- How to ensure end-to-end Exactly-Once processing
Real-Timeliness
To avoid such troubles, Doris implements a Stream Write method, which works as follows:
- A Flink task, once started, asynchronously initiates a Stream Load HTTP request.
- The data is transmitted to Doris via the chunked transfer encoding mechanism of HTTP.
- The HTTP request ends at Checkpoint, which means the Stream Load task is completed. Meanwhile, the next Stream Load request will be asynchronously initiated.
- Repeat the above steps.
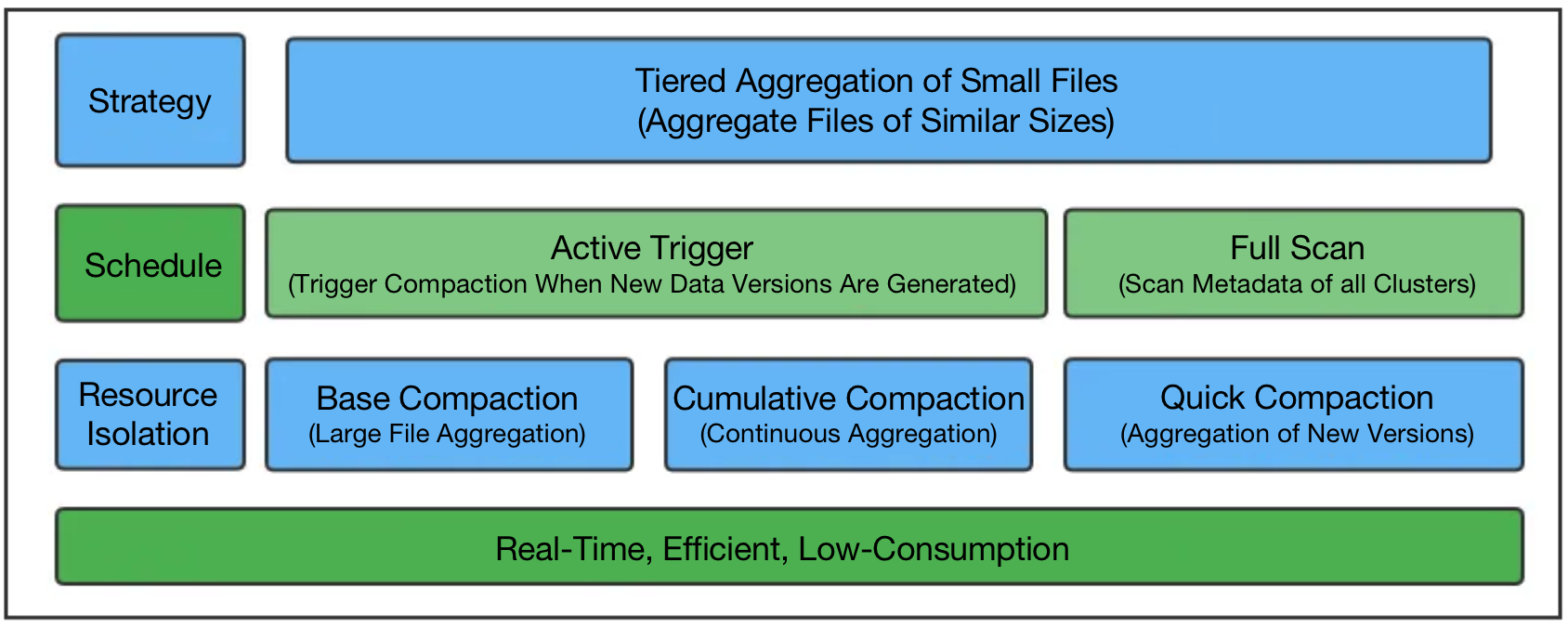
- Quick Aggregation of Data Versions
Highly concurrent writing of small files can generate too many data versions in Doris and slow down data queries. Thus, Doris has enhanced its data compaction capability in order to quickly aggregate data.
Firstly, Doris introduced Quick Compaction. Specifically speaking, data compaction will be triggered once data versions increase. Meanwhile, by scanning the metadata of tablets, Doris can identify those tablets with too many data versions and conduct compaction correspondingly.
Secondly, for the writing of small files, which happens in high concurrency and frequency, Doris implements Cumulative Compaction. It isolates these compaction tasks from the heavyweight Base Compaction from a scheduling perspective to avoid mutual influence between them.
Last but not least, Doris adopts a tiered data aggregation method, which ensures that each aggregation only involves files of similar sizes. This greatly reduces the total number of aggregation tasks and the CPU usage of the system.
Exactly-Once
The Exactly-Once semantics means that the data will be processed once and only once. It prevents the data from getting reprocessed or lost even if the machine or application fails.
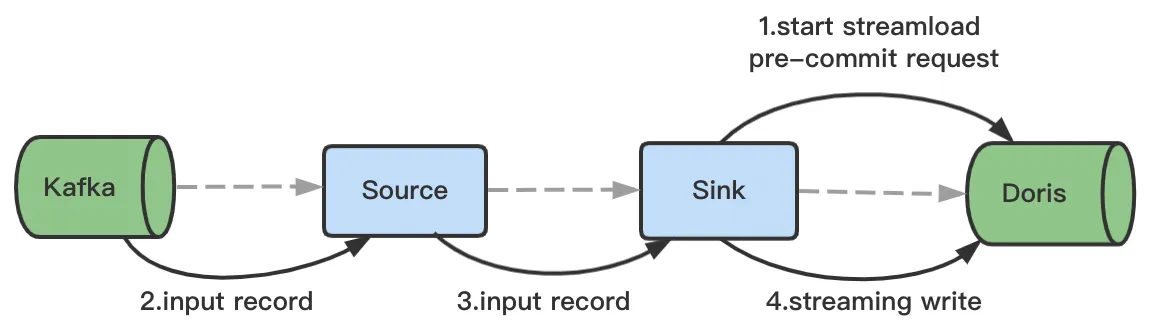
Flink implements a 2PC protocol to realize the Exactly-Once semantics of Sink operators. Based on this, the Flink-Doris Connector in Doris implements Stream Load 2PC to deliver Exactly-Once processing. The details are as follows:
- A Flink task will initiate a Stream Load PreCommit request once it is started. Then, a transaction will be opened, and data will be continuously sent to Doris via the chunked mechanism of HTTP.
- The HTTP request ends at Checkpoint and the Stream Load is completed. The transaction status will be set to Pre-Committed. At this time, the data has been written to BE and become invisible to users.
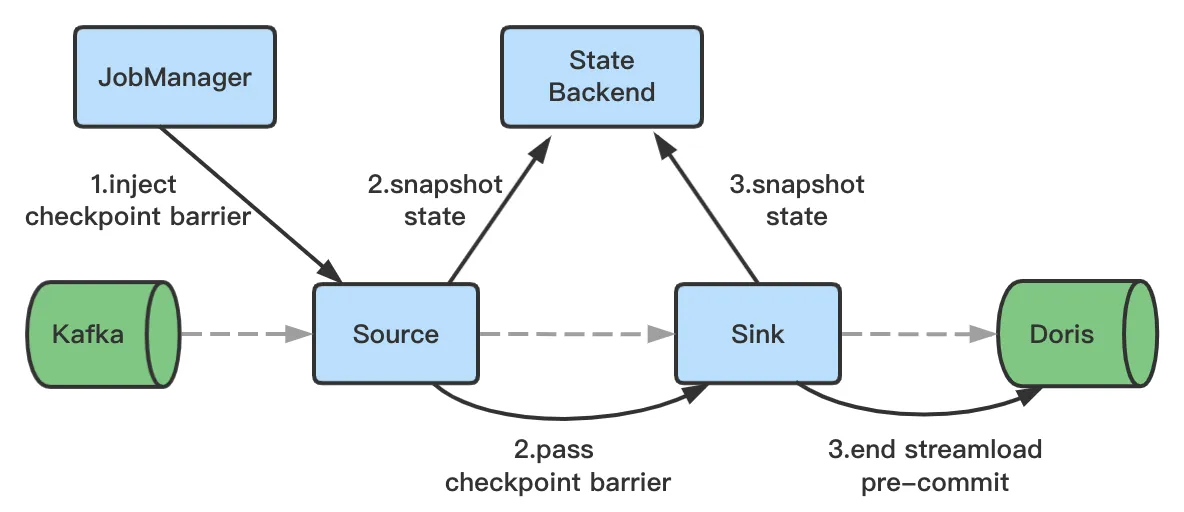
- The Checkpoint initiates a request and changes the transaction status to Committed. After this, the data will become visible to users.
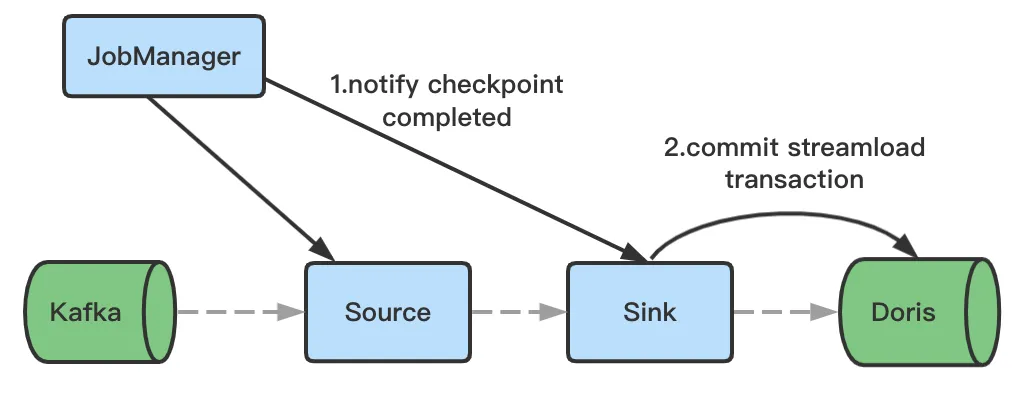
- In the case of Flink application failures, if the previous transaction is in Pre-Committed status, the Checkpoint will initiate a rollback request and change the transaction status to Aborted.
Performance of Doris in High-Concurrency Scenarios
Scenario Description
Import data from Kafka using Flink. After ETL, use the Flink-Doris Connector for real-time data ingestion into Doris.
Requirements
The upstream data is written into Doris at a high frequency of 100,000 per second. To achieve real-time data visibility, the upstream and downstream data needs to be synchronized within around 5s.
Flink Configurations
Concurrency: 20
Checkpoint Interval: 5s
Here’s how Doris does it:
Compaction Real-Timeliness
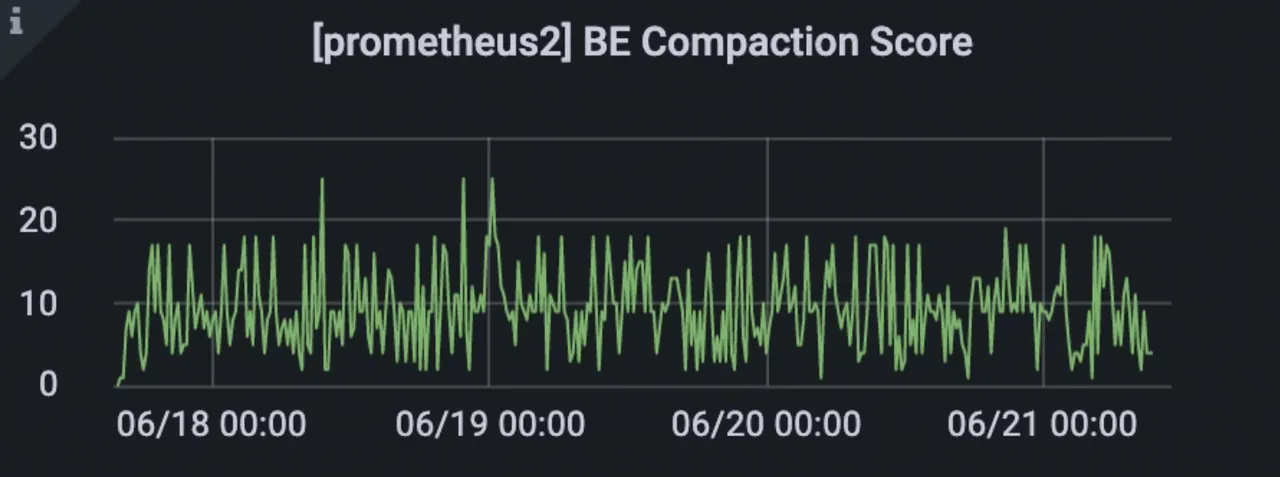
As the result shows, Doris manages to aggregate data quickly and keep the number of data versions in tablets below 50. Meanwhile, the Compaction Score remains stable.
CPU Usage
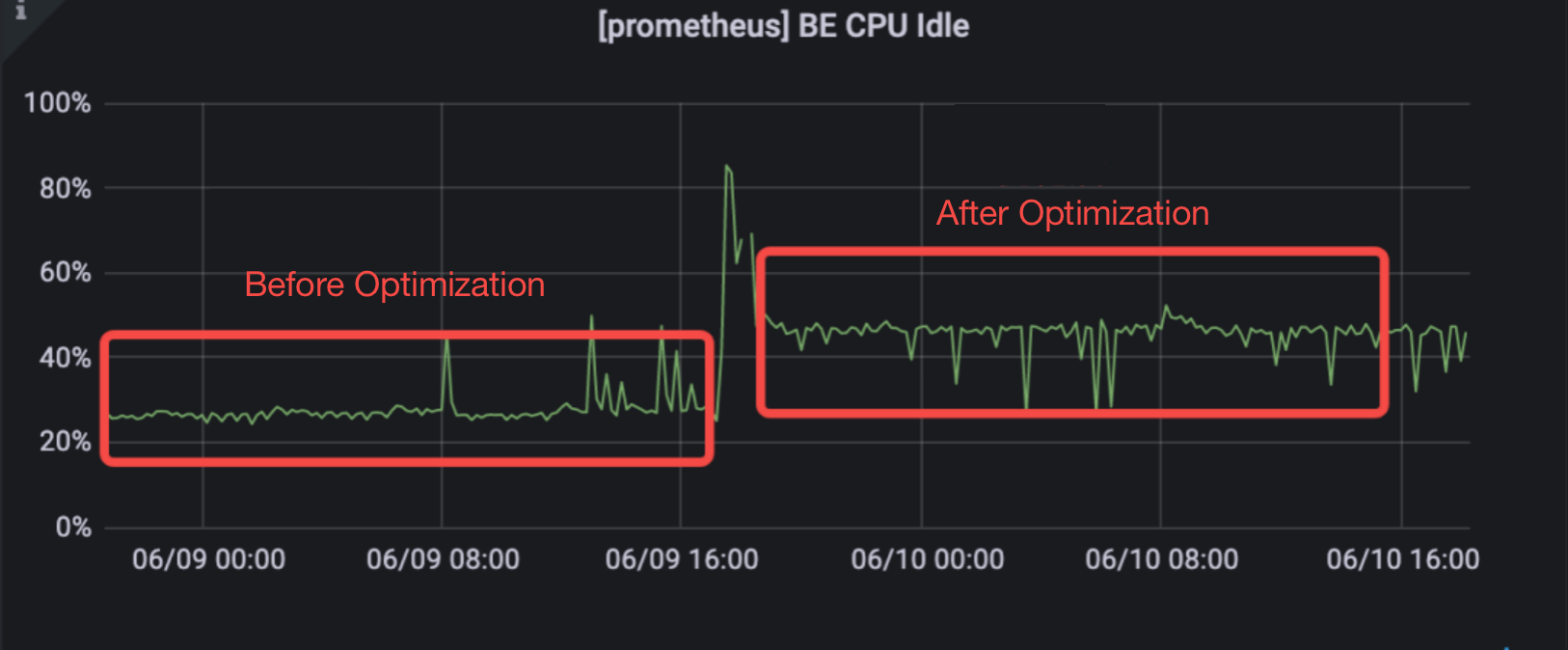
After optimizing the compaction strategy of small files, Doris reduces CPU usage by 25%.
Query Latency
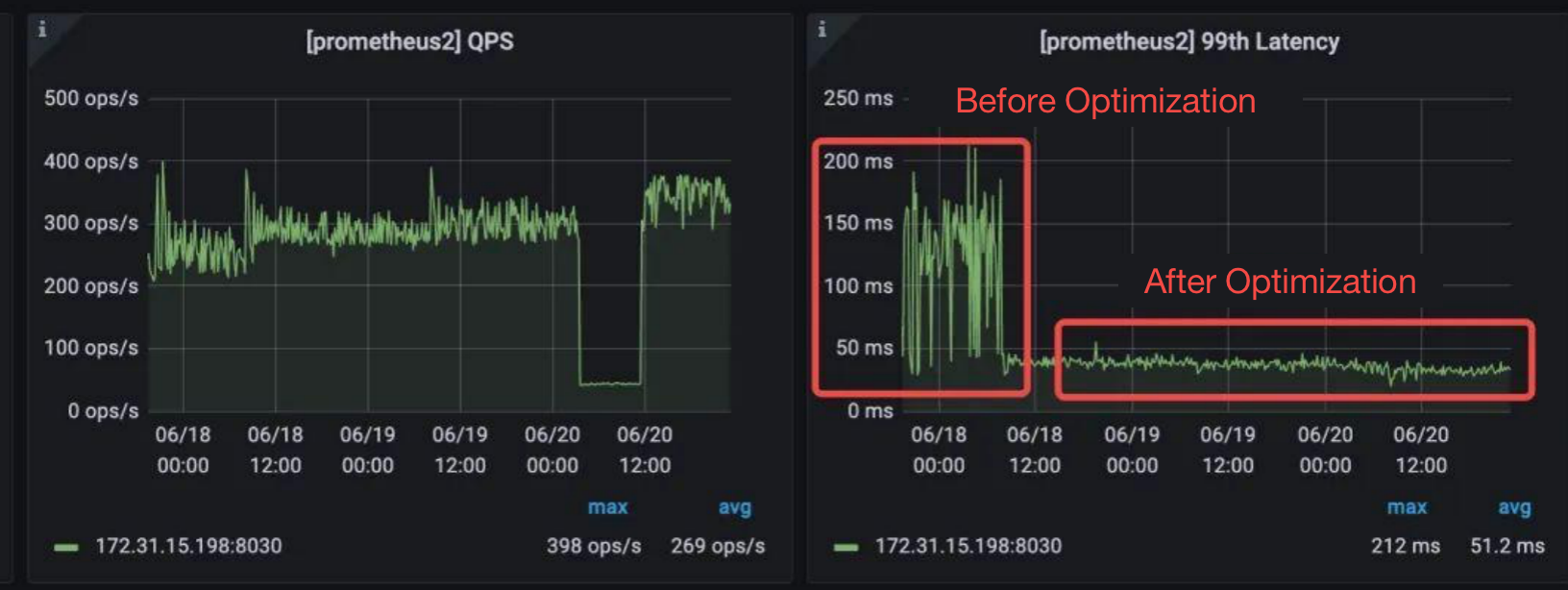
By reducing the CPU usage and the number of data versions, Doris arranges the data more orderly and thus enables much lower query latency.
Performance of Doris in Low-Latency Scenarios (High-Level Stress Test)
Description
- Single-BE, single-tablet Stream Load stress test on the client side
- Data real-timeliness <1s
Here are the Compaction Scores before and after optimization:

Suggestions for Using Doris
Low-Latency Scenarios
As for scenarios requiring real-time data visibility (such as data synchronization within seconds), the files in each ingestion are usually small in size. Thus, it is recommended to reduce cumulative_size_based_promotion_min_size_mbytefrom the default value of 64 to 8 (measured in MB). This can greatly improve the compaction performance.
High-Concurrency Scenarios
For highly concurrent writing scenarios, it is recommended to reduce the frequency of Stream Load by increasing the Checkpoint interval to 5–10s. This not only increases the throughput of Flink tasks, but also reduces the generation of small files and thus avoids extra pressure on compaction. In addition, for scenarios with less strict requirements for real-timeliness (such as data synchronization within minutes), it is recommended to increase the Checkpoint interval to 5–10 minutes. In this way, the Flink-Doris Connector can still ensure data integrity via the 2PC+Checkpoint mechanism.
Conclusion
Apache Doris realizes data real-timeliness by its Stream Write method, transaction processing capability, and aggregation of data versions. These techniques help it reduce memory and CPU usage, which enables lower latency. In addition, for data integrity and consistency, Doris implements Stream Load 2PC to guarantee that all data is processed exactly once. This is how Doris facilitates quick and safe data ingestion.
Source link